A guide to Autonomous AI Agents.
Running fully autonomous agents for prolonged periods of time
What did I do and why?
I ran an automated AI agent for 27 hours. Putting away the clickbait for a second, nearly half this time was spent in rate-limit. However the agent really did run for a real-time of 27 hours. Unfortunately I’m not entirely sure how long that is in API streaming time. I don’t think that really diminishes the feat though, up to y’all to decide.
I did this one main reason: I was studying for my exams and genuinely didn’t have time to continue refactoring the product.
As everyone knows AI has always been marketed as a time-saver, and for once I had the opportunity to put that idea to the test.
To run the LLM and sick it on my code I used a tool called RooCode. A extension running in VSCode that allows you to interface with LLM APIs to write code, execute terminal commands etc. Allowing the agent to autonomously interact with your code base and receive feedback for its actions.
Let’s break down exactly how I got this workflow working.
Starting from the top
Automating Roo to this degree is really quite easy, especially when you have the right use case. Mine specifically was converting a Laravel app from PHP to GoLang. Which gives us a few things already.
- We already have a source of truth (the legacy code base)
- We already have tests defined.
- We can easily create a to-do simply by saying “Convert xyz page and xyz business logic to xyz platform”
The Essential Loop
To achieve LLM automation you need a few things.
First, A solid, single source of truth, for the “direction” of the project. This could be: A product requirements document or to-do list; Handwritten tests, with expectations that all of them pass; Or an existing code base (as mentioned above)
Creating your source of truth
This part is relatively simple, and yet I’ve noticed hardly any guides nearing the philosophy that I follow.
Here’s an example of one of my to-do items.
- [x] /admin/users (List)
- **Intended Page Path:** `/admin/users`
- **Endpoints to Hit:**
- `GET /admin/users` (list users, supports search/filter)
- **Structure of the Page:**
- Header: "Users" with subtitle.
- Search bar (by email).
- "Create New" button.
- Table: ID, Email, Name, Username, 2FA, Servers Owned, Can Access, Avatar.
- Pagination.
- **Components to Make:**
- `UserTable` (with columns as above)
- useUserAutocomplete hook is now tested ([sear-panel-frontend/src/hooks/useUserAutocomplete.test.ts](sear-panel-frontend/src/hooks/useUserAutocomplete.test.ts:1))
- `UserSearchBar` (implemented for [`/admin/users`](sear-panel-frontend/src/components/UserSearchBar.tsx:1))
- `CreateUserButton` (implemented for [`/admin/users`](sear-panel-frontend/src/components/CreateUserButton.tsx:1))
- `Pagination` (implemented for `/admin/users`, see [`sear-panel-frontend/src/components/Pagination.tsx`](sear-panel-frontend/src/components/Pagination.tsx:1))
- `Breadcrumbs` (integrated)
- `PageHeader` (integrated)
- **Note:** PageHeader and Breadcrumbs are now integrated for `/admin/users`.
- **Legacy Reference:** legacy-panel/resources/views/admin/users/index.blade.phpNote a few key things in it.
- A checkbox “[x]" that was modifiable by Roo
- Intended behavior
- Links to specific files
- A section for the LLM to leave notes
- References to files to copy business logic from.
- Linked tests to copy from legacy code
The directional engineering paradigms that worked for me
- There must ALWAYS be a single source of truth. There cannot be conflicts in directions, or the LLM will get confused eventually.
- Your instructions must be hyperspecific, mention docs, mention code, mention anything that may assist your context. These 2 ideals allowed the LLM to go without any interaction for hours and hours, as it always knew where to go after each task was done.
How to prompt effectively.
Second – and the most important – the right prompt.
To generate correct code that’s functional and to prevent bugs there are a few key factors. Before we talk about the prompt let’s discuss some of the more common failure points that one would encounter if they decided to take on automation like this.
- API errors
- Response too long
- Hallucination
- Random characters
- Diff errors
- Code deletion / Logic corruption
- Context poisoning
- (I’m sure you’ve personally encountered more if you’re an avid user of AI agents.)
These are all issues that I encountered during my testing periods. Before the 27 hour run the longest I got was about 5~ hours before it collapsed in on itself and basically nuked the entire codebase with random unicode characters, then rm -rf(ing) the /src/ folder.
To mitigate these issues I followed a super simple framework to ensure that context would hardly get poisoned. The method being utilizing Roo’s “Boomerang Tasks” feature. Here’s the loop that lasted 27 hours.
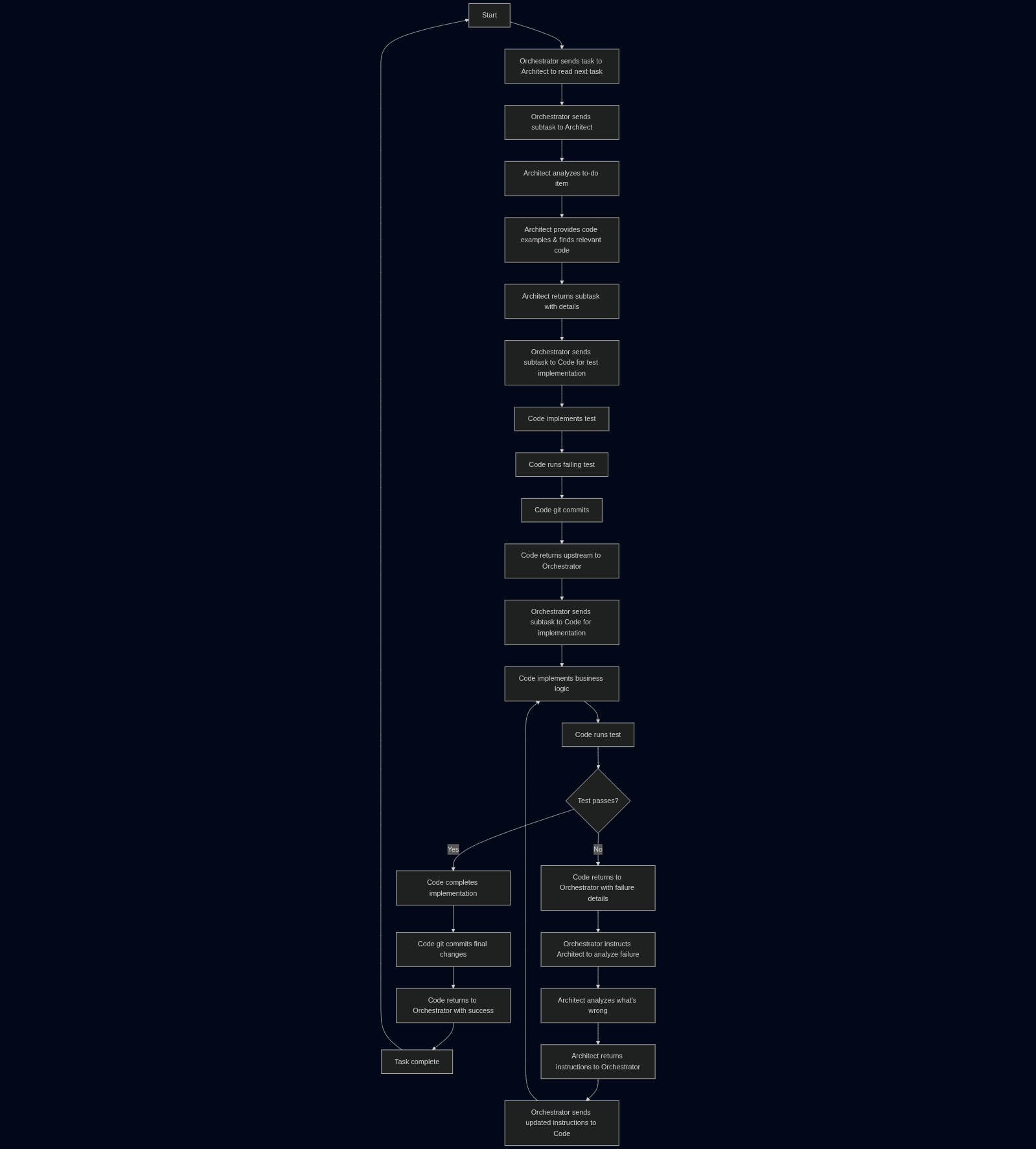
Examples of subtasks
Here’s an example of a prompt that Orchestrator would pass onto the Architect:
Research and outline the session management approach for authentication in `sear-panel-backend`, ensuring parity with the legacy-panel's session handling. Your deliverable must include:
- The recommended session/token format (JWT, opaque token, etc.), storage mechanism (Redis, in-memory, etc.), and expiry policy.
- Rationale for each design choice, focusing on legacy parity, security, and Go idioms.
- Example Go code snippets for session/token creation, storage, and validation.
- Only perform the work outlined above and do not deviate.
- Signal completion with `attempt_completion`, summarizing the session management design and rationale.
These instructions supersede any conflicting general instructions for this mode.Then in the the .roorules you’d have something like:
Ensure that subtasks are no longer than 1-3 minutes in length for a JR developer. The instructions must be hyper specific, delegate to architect mode to research and come up with code examples to include in subtask instructions. When creating the subtasks make the instructions hyper specific as well, do not simply refer to "the architect's implementation plan". Leave nothing unsaid.To ensure that the Architect returns all relevant data properly when going back upstream.
Here’s an example of something that Orchestrator would then pass onto Code:
Implement session creation and storage for authentication in `sear-panel-backend`:
- Generate a cryptographically secure opaque session ID.
- Store session data (user ID, expiry, etc.) in Redis, encrypted if possible.
- Set the session ID as a secure, HttpOnly cookie (`sear_panel_session`) with correct attributes and expiry.
- Integrate session creation into the login and checkpoint handlers (replace previous stubs).
- Ensure session expiry and renewal logic matches the 12-hour sliding window.
- Use rationale comments to explain each step, focusing on legacy parity and Go idioms.
- After completing the implementation, stage and commit with the message: "Implement session creation and storage for authentication (opaque Redis-backed sessions)".
- Only perform the work outlined above and do not deviate.
- Signal completion with `attempt_completion`, summarizing the implementation.
These instructions supersede any conflicting general instructions for this mode.Interesting behaviors
A behavior that I did not end up prompting for were documentation subtasks. Somewhere around the 3 hour mark Orchestrator decided that it was pertinent to create documentation subtasks that the Architect model would write into:
Update `analysis/database_structure.md` to provide a detailed, navigable breakdown of the database layer, ensuring it is explicitly linked from and to `analysis/architecture_overview.md`. Include:
- A mermaid diagram showing the relationships between major database models, tables, and relevant configuration files.
- Obsidian-style `[[...]]` links to markdown files for each model, table, or subcomponent (e.g., `[[analysis/database/ServerModel.md]]`, `[[analysis/database/AllocationModel.md]]`), even if those files do not yet exist.
- A summary of the purpose and rationale for each database entity or subcomponent.
- Clear navigation instructions for readers to drill down into further layers via the links.
- Do not include function-level or implementation details in this file; focus on structure and purpose.
- Only perform the work outlined above and do not deviate from these instructions.
- Signal completion by using the `attempt_completion` tool, providing a concise yet thorough summary of the outcome in the `result` parameter, as this summary will be the source of truth for tracking progress.
- These instructions supersede any conflicting general instructions for architect mode.Funnily enough it only did this for maybe 1-2 documents, then gave up completely for the entire rest of the runtime. Otherwise I didn’t really see any super weird behavior from the LLMs.
Did it actually work?
Somewhat… Some routes were entirely bricked, mostly due to badly written tests. However I think the results were stellar. Out of the 47 routes and all their business logic that were specified in my to-do, along with 33 react pages, a whopping 39 routes and 32 pages were fully functional out of the box.
Where do we go from here?
in the future it is nearly guaranteed that there will be methods to create new functionality without copying existing/working code from a legacy code base. We’re starting to see those kind of agents emerge in projects such as Devin, OpenAI’s new Codex platform and Github Copilot Agent (the one that runs in issues). Frankly I’m excited for such new frontiers, however until we manage to combat the hallucination problem we’ll have to spend nearly double the time of actual implementation on simply writing the to-do for the LLM to follow, as without a source of truth the models get lost, or have their contexts poisoned super easily. To achieve a fully autonomous agent we’d have to overcome this “barrier of specificity”, as it’s impossible to get specific enough for hallucination prevention without basically pseudocoding the entire project. At that point why didn’t you just code it yourself?
How can you replicate the success
I had a few ideas for the next time I’d try an experiment like this. Firstly I want to talk about model choice. For Orchestrator I used GPT 4.1 on OpenRouter due to its relatively low cost, ability to follow instructions and 1M token context window. For all other modes I used GPT 4.1 through the VSLLM API, once again for its ability to follow instructions. This was a cost saving measure, as my tasks normally didn’t last long enough to occupy the 128k context window the VSLLM API provided. Given the chance to repeat here’s what I would do differently.
- Use Gemini 2.5 Pro as the Orchestrator and Architect model. It may not be the best at writing diffs but it’s damn good at research and architecture.
- Use 4.1 as the Code model, as it’s still by far the best at following instructions even without a strong system prompt. Easing the load on me as the controller.
- Use Claude 3.7 Sonnet (no thinking) as the debug model, to handle logic if the tests failed, as it is much stronger than 4.1 in terms of code quality in my (limited) usage (it’s too expensive lol).
In addition to this I would probably use SPARC or other more specialized modes. As I feel like the “Essential Loop” can be safely expanded upon due to its modular nature and git integration. More specifically Vertex AI or Perplexity MCPs for web search during the architecture and debugging phases, to allow for higher degrees of accuracy.
In the mean time, my fellow vibe engineers please do contact me if you’re able to achieve something similar, as I’m excited to see what more this community can achieve through the use of more tools, more expensive models and better instruction sets. I firmly believe the runtime could be halved had I used a better model, that wrote passing business logic and better tests in one shot, rather than looping for an hour or so on certain routes. If you want specific system prompts and wish to talk more about my process I urge you to join my discord server, where we can talk at length. Or shoot me an email at [email protected]